
I feel like most of the layoffs and the flooded market happened in the US. Judging by the name, bleistift is from the EU…
- 4 Posts
- 466 Comments
Joined 3 years ago
Cake day: January 13th, 2022
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 51·11 months ago
51·11 months agoYou say that like anyone knows how Fahrenheit even works.
 14·11 months ago
14·11 months agoIn principle, I agree, but I feel like part of that is just AAA vs. indie.
AAA games need to provide lots of lukewarm content, because many more casual players will buy them and expect much bang for their buck + haven’t seen this lukewarm content a million times already.
On the other hand, indies will basically only be bought by people more enthusiastic about the hobby. As such, they have to pick out one or two aspects and excel at them, so that it’s something new for that crowd.
Hello Games was indie and unknown at the time, so likely only attracted that gaming enthusiast crowd, which would have been more easily bored by the extremely lukewarm content in Starfield.
 3·11 months ago
3·11 months agoIt took maybe 10 minutes or so for a 256 GB hard drive for me, if I remember correctly.
That was an SSD, though, so yeah, mileage would definitely vary on an HDD.
Hmm, what does that full format do? Write zeros over everything?
Personally, I would run
shredon the root filesystem. It’s a tool specifically intended for properly deleting data (overwrites it with random data multiple times).
 1·11 months ago
1·11 months agoOf course, yes. I’m just explaining why there’s more political motivation to not be hit by a car than a motorcycle.
A motorcycle has a higher chance of killing its rider rather than bystanders, when compared to cars.
The graph is from this article: https://peakoilbarrel.com/carrying-capacity-overshoot-and-species-extinction/
…which cites the article you linked, but also this paper: https://vaclavsmil.com/wp-content/uploads/PDR37-4.Smil_.pgs613-636.pdf
It would be nicer, if it was in some renown journal, so we’d know some sort of peer review has taken place. This certainly could still be entirely made up. But it looks a lot more convincing/sourced than most articles.

 2·11 months ago
2·11 months agoWell, typically, being married for 60 years would also involve not dying for the past 70+ years…
I don’t think, there’s currently any plans to introduce a non-JS API for accessing the DOM. It would just take an insane amount of implementation work + documentation.
But frameworks can generate access code for you, so you don’t actually need to write any JS yourself. Rust is quite far ahead in this regard, thanks to the
wasm-bindgenlibrary.

I mean, so far, all of them require tons of humanly produced data.
Discriminative AI (deep learning et al) requires humans to label data for hours on end, per use-case.
And generative AI (LLMs et al) require just insane amounts of human works to copy from, albeit not necessarily limited to individual use-cases.I guess, what I’m saying is that the ratio of how much labor humans (involuntarily) invested into AIs, compared to the labor these AIs actually perform, is likely a lot higher than 70%.
It’s a thing here in Europe. I’m guessing, because our walls are generally concrete, we usually either throw on decorative plaster or a wallpaper, to make it feel a bit warmer and have a uniform surface which accepts paint more readily.
It’s even quite common that if you rent an appartment, that the walls have wallpaper on them, which is painted with a fresh coat of white paint every time someone moves out and the next folks move in.
And then some people, after they move in, will just paint (some of) the walls in a different color, if they feel like not living in pure white…
Well, this isn’t a problem for smaller, less centralized services, so that might be an answer. Obviously not an answer big corporations will bring to the table, but ultimately, it might simply be among the reasons why users do still prefer smaller services.
I have my repos on Codeberg and one of the ‘disadvantages’ is that, well, it’s a non-profit, so I genuinely don’t want to waste their resources.
They ask you to only host open-source repos there, meaning that using it for backups of shitty personal projects, even if I would throw in an open-source license, is just out of the question for me.And that has weirdly been a blessing in disguise. Like, if it’s not useful for humanity to see, do I really care to keep it around forever?
And I’ve had three projects now where I felt an obligation to push them over the finish line of actually making them a useful open-source project. Which had me iron out some of the usability shortcuts I took, made me learn a good amount of code quality stuff and of course, just feels good to complete.
 21·11 months ago
21·11 months agoIt looks similar in structure to JSON:
{ "attr": { "size": "62091", "filename": "qBuUP9-OTfuzibt6PQX4-g.jpg", ... }; "key": "Wa4AJWFldqRZjBozponbSLRZ", ... }So, it might be some JSON meta language. I just find it weird that it seems to contain all data, so you wouldn’t use this for validating or templating JSON.
But ultimately, it also means with a handful of regex replacements, you could turn this particular file into JSON. Might make building your own parser almost trivial…
I guess, the real question is: Could we be using (simplistic) LLMs on a phone for predictive text?
There’s some LLMs that can be run offline and which maybe wouldn’t use enormous amounts of battery. But I don’t know how good the quality of those is…
You’re in the No Stupid Questions community. Think about rule 7 in particular.



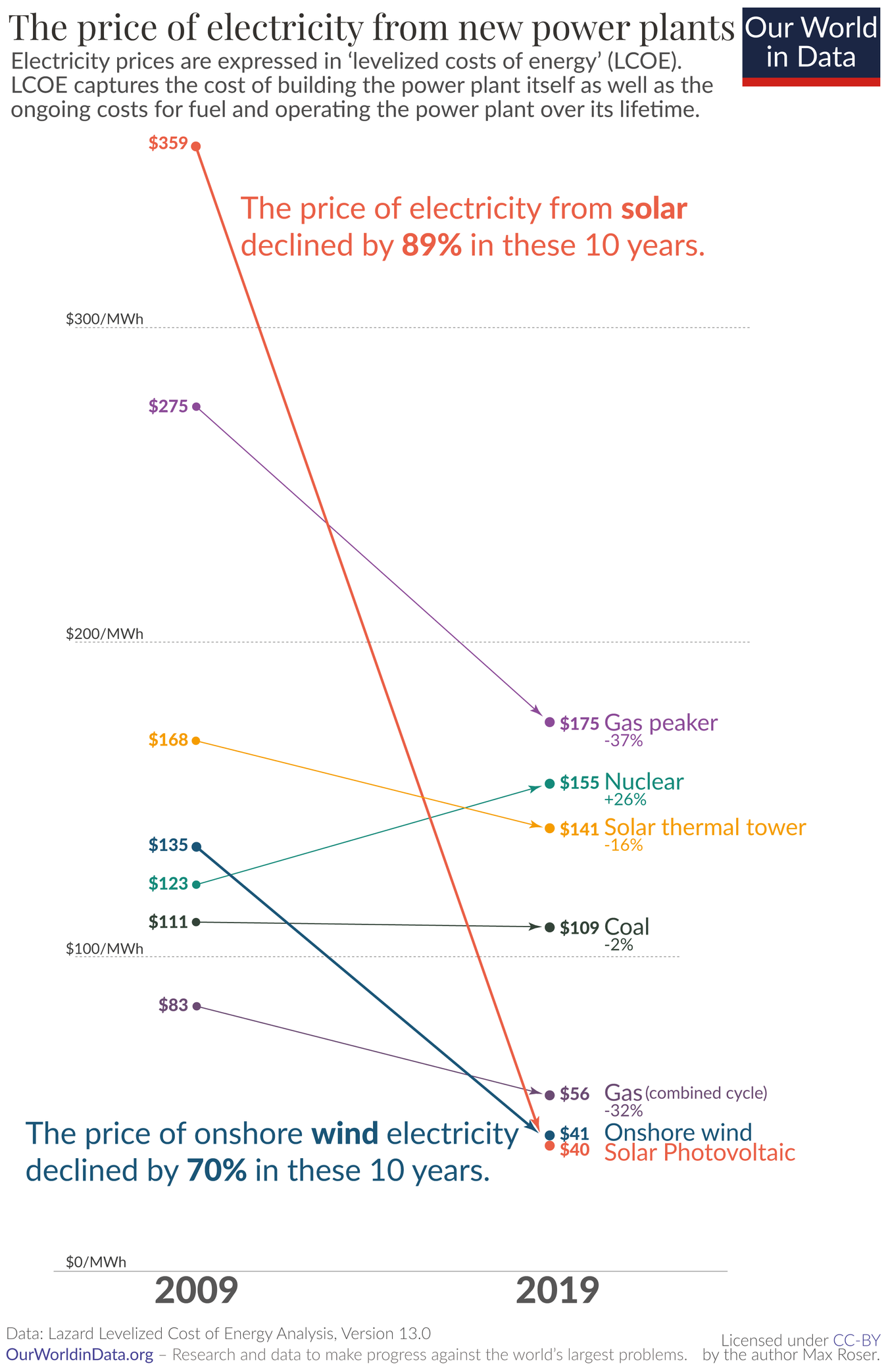{kind=link}
{kind=link}
Well, to reference Julia Evans another time:
headandHEADare specifically the third meaning of ‘branch’, i.e. the newest commit on a branch, but can also refer to a commit not on a branch, when in that detached head state.And while I’m not enamored with these names either, I can’t think of a word that I like better for this meaning.